Metrics
Complexity
One important aspect to quantify with an XAI method is to know if all features are relevant to compute attributions. A more concise explanation, with high scores given to a small subset of features, would be more understandable for the user.
Complexity
Complexity (original paper) computes the fractional contribution of each feature to the total attribution by taking the Shannon entropy of these fractional contributions.
The fractional contribution of feature i is defined as:
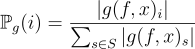
with S the ensemble of features considered, g the explaination function, f the predictor and x a specific instance.
We can now write complexity as:
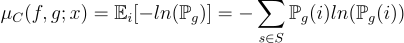
The objective is to minimize complexity, with one feature having a contribution approaching 1 and the others approaching 0. If the attributions were uniformly distributed between features, the complexity would have a maximum value which is opposed to the desired goal.
In our implementation, we standardize complexity by the total number of features to get a final score with values between 0 and 1.
Sparseness
Sparseness (original paper) is another way of quantifying the concentration of explanations on specific features.
With 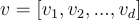 an attribution vector with non-negative values sorted in non-decreasing order, sparseness is defined as the following Gini Index:
an attribution vector with non-negative values sorted in non-decreasing order, sparseness is defined as the following Gini Index:
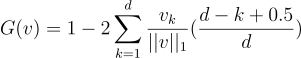
By definition, 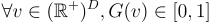 . The ideal case would be to have one
. The ideal case would be to have one 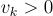 and the others 0, leading to G(v)=1. If all attributions were uniformly distributed with a non zero value, it would in result in G(v)=0 which is not wanted.
and the others 0, leading to G(v)=1. If all attributions were uniformly distributed with a non zero value, it would in result in G(v)=0 which is not wanted.
Faithfulness
An explanation method should also verify the property of Faithfulness. It means that attributions should be aligned with the important features for the model prediction. Most faithfulness metrics quantifies this aspect by perturbating a sample relatively to feature importances and compare the way the prediction of the model changes.
Faithfulnesss correlation
Faithfulness Correlation (original paper) computes the correlation between the sum of the attributions of 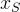 and the difference in model prediction, being an input with a subset of indices S features replaced by a baseline value.
and the difference in model prediction, being an input with a subset of indices S features replaced by a baseline value.
With a predictor f, an explanation function g, an instance x and a subset of features S, faithfulness correlation is defined by:
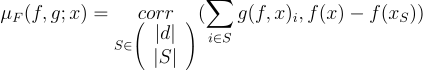
All subsets of 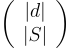 are not explored entirely and the size of subsets |S| is fixed. By definition, the values of the correlation lie in [-1,1] with the ideal case being
are not explored entirely and the size of subsets |S| is fixed. By definition, the values of the correlation lie in [-1,1] with the ideal case being 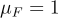 .
.
In our experiments, we use a percentage of the total number of features for the subset size |S| with a default value of 20% which we found to yield sufficiently discriminative results between different explainability methods. We choose to repeat this process for 20 iterations which we consider a good trade-off between computation time and quality of the approximation.
Area Under the Threshold Performance Curve
AUCTP (original paper) computes the AUC of the curve
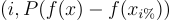
with P a performance measure and 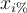 the input with i% most import features replaced by a baseline,
the input with i% most import features replaced by a baseline,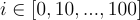 . We expect the performance curve to drop significantly after the removal of the most important features and thus giving an objective of minimizing the AUC.
We standardize the final results by the number of features in the dataset to yield comparable results across different tasks.
. We expect the performance curve to drop significantly after the removal of the most important features and thus giving an objective of minimizing the AUC.
We standardize the final results by the number of features in the dataset to yield comparable results across different tasks.
Comprehensiveness
Comprehensiveness (original paper) represents the impact of replacing most important rationales by a baseline. It is written as
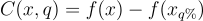
with 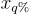 the input x with q% most important features replaced by a baseline. Intuitively, as we remove the most important rationales or features by attribution values, we expect a significant increase of the difference in prediction between the perturbed sample and the input with all features.
the input x with q% most important features replaced by a baseline. Intuitively, as we remove the most important rationales or features by attribution values, we expect a significant increase of the difference in prediction between the perturbed sample and the input with all features.
Sufficiency
Sufficiency (original paper) represents the impact of adding most important features to a baseline in the predictive behavior. It is the counterpart of comprehensiveness as it is defined as
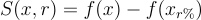
with 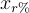 the input x with only r% most important features added starting from a baseline. Intuitively, when we add the most important features by attribution values, we expect the prediction to be closer to the prediction for the input with all features.
the input x with only r% most important features added starting from a baseline. Intuitively, when we add the most important features by attribution values, we expect the prediction to be closer to the prediction for the input with all features.
For both Comprehensiveness and Sufficiency, we decide to use a ratio of 30% for q and r.
Monotonicity
Monotonicity (original paper) quantifies the improvement after adding each feature without replacement.
With 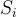 an ensemble of i most important attributions, an instance x and a predictor function f, monotonicity is defined as:
an ensemble of i most important attributions, an instance x and a predictor function f, monotonicity is defined as:
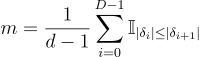
with 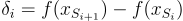 Because it is defined as the proportion of marginal feature improvement, an ideal monotonicity would have a value of 1, where each feature would have a better marginal improvement than a less important feature.
Because it is defined as the proportion of marginal feature improvement, an ideal monotonicity would have a value of 1, where each feature would have a better marginal improvement than a less important feature.
Infidelity
Infidelity (original paper) quantifies faithfulness by computing the effect of significant perturbations on the predictive function. It is computed as the MSE between the attributions multiplied by a perturbation and the difference between the predictive function taken on the input and the perturbed input.
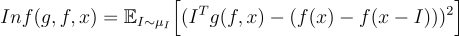
where I is a significant perturbation around x. The choice of a perturbation needs to be chosen according to the task considered, popular choices are the difference between input and a baseline being often a Gaussian centered noise with a certain standard deviation.
For the perturbation, we follow this choice with a standard deviation being the average distance between pair of points in the dataset like in this paper.
Robustness
Robustness quantifies the degree of stability of the explainability method. For similar instances, we want computed explanations to be also similar. Most of robustness metrics involve adding a small perturbation to a sample and computing the relative change in the attributions, with a low change desired.
Sensitivity
Sensitivity (original paper) measures the effect of small perturbations on the predictive function. It is computed as the gradient of the explanation function with respect to the input.
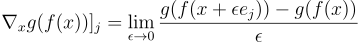
with 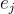 is the basis vector of coordinate j.
This expression is often derived to take the Max-Sensivity within a sphere around the input of radius r.
is the basis vector of coordinate j.
This expression is often derived to take the Max-Sensivity within a sphere around the input of radius r.
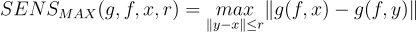
It is shown that Max-Sensitivity is a more robust metric than a local Lipschitz continuity measure as the later can be unbounded for neural networks.
In our experiments, we sample the perturbed inputs in a sphere centered around the original sample with a radius being the same as the one chosen for Infidelity with the average distance between pairs.